

Introduction
This article is based on our expertise in building AI vision models and deploying them in customized real time video processing pipelines. In our experience,a realtime vision Ai pipeline enables fast results and saves on GPU hardware usage cost.
This is a comparative study between two popular frameworks, which we have customized and deployed extensively in our Vision Ai based products.For this study, we have used an application which detects multiple faces using a face detection model and creates face masks to precisely blur face contours. Our aim is to maximize the throughput and achieve real time frame processing speeds.
AI Vision Solution Frameworks
An AI vision solution requires pre and post processing modules apart from the Vision model. A solution architect has to select an appropriate framework for deploying an end to end pipeline with all the processing stages and AI model.
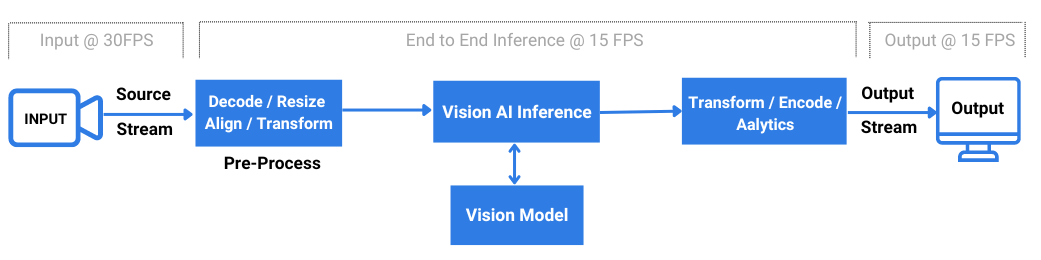 Components of a AI Video Processing Pipeline
Components of a AI Video Processing Pipeline
A single video stream generates around 25 – 30 frames per second. Vision AI inference pipeline has to process these frames/images with minimum latency. For real time performance, the pipeline has to process input frames within the input frame rate. Throughput is measured in FPS( frames processed per second). We will explore pros and cons of two broad deployment strategies, Deepstream/ Gstreamer/ C++ plugin based pipeline Vs. Python/Pytorch inference script.
Python/Pytorch based inference script is a popular approach during the proof of concept stage of a solution. Any vision Ai model can easily be used in inference mode with few lines of python code. Pytorch/Opencv provides most of the frame transform operations needed for pre/post processing of frames. Generally python/pytorch based solutions are slow in processing frames and can’t be scaled easily.
Overall this approach contains one main loop which contains step by step processing functions along with model inference code. It doesn’t become a true pipeline where multiple stages can work in parallel fashion to accomplish overall tasks faster.
A good example of a pipeline is an automobile assembly line which has multiple independent stages and at any given time multiple cars will be going through this pipeline. This is essential to achieve efficiency.
Deepstream is a framework from NVIDIA which is used to deploy AI vision models on Nvidia’s GPU hardware. It has inbuilt plugins for various tasks required for model inference and frame processing.
Plugins work as independent pipeline stages which can process frames in parallel. This framework promises faster performance based on true pipeline architecture.
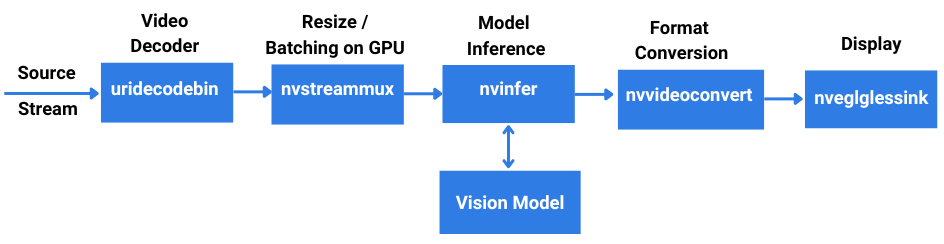 A Deepstream Pipeline For AI Video Analytics
A Deepstream Pipeline For AI Video Analytics
These plugins can be customized for different requirements or new ones can be developed from scratch.
Nvinfer is the main inference plugin in Deepstream framework. By default, It supports object detection models in Onnx or TensorRT format for running inference.
For other computer vision tasks, this plugin needs to be customized based on the model’s input and output requirements. We have developed a customized version of Nvinfer plugin for running our version of face detection model and blurring out detected faces in each frame.
Performance Comparison:
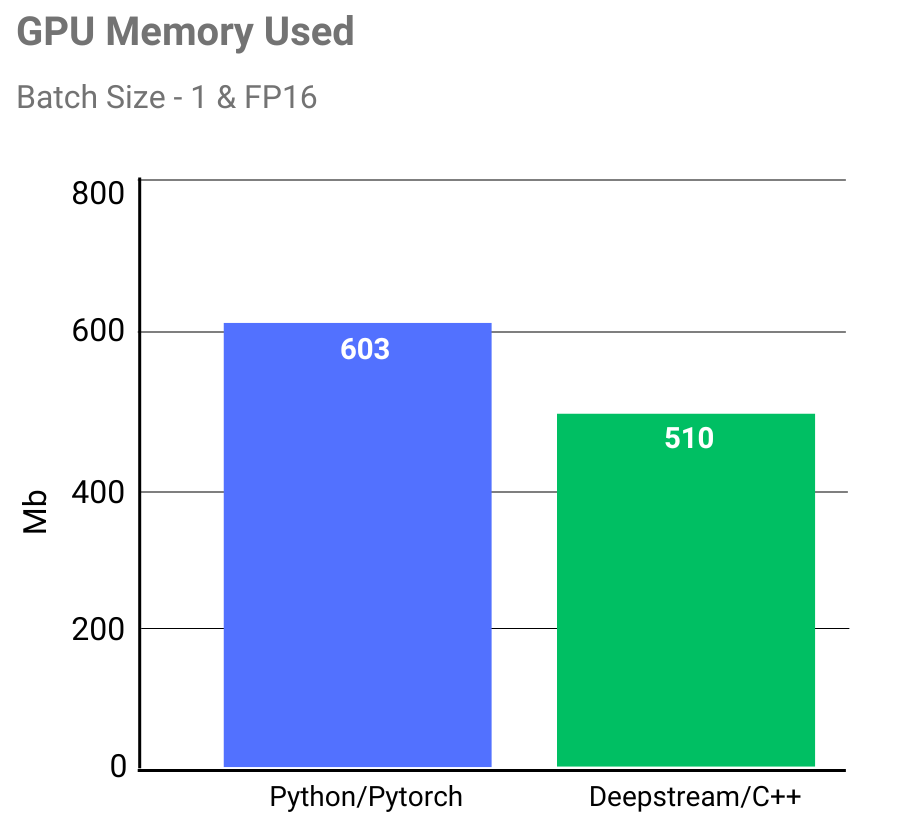
Deepstream pipeline requires 15% less GPU memory for end to end execution. Internally deepstream uses NVIDIA TensorRT runtime, which claims to optimize GPU memory usage by fusing model nodes and reusing tensor memory efficiently.
Demo Video
Original video Source and license – https://github.com/intel-iot-devkit/sample-videos/tree/master
Conclusion
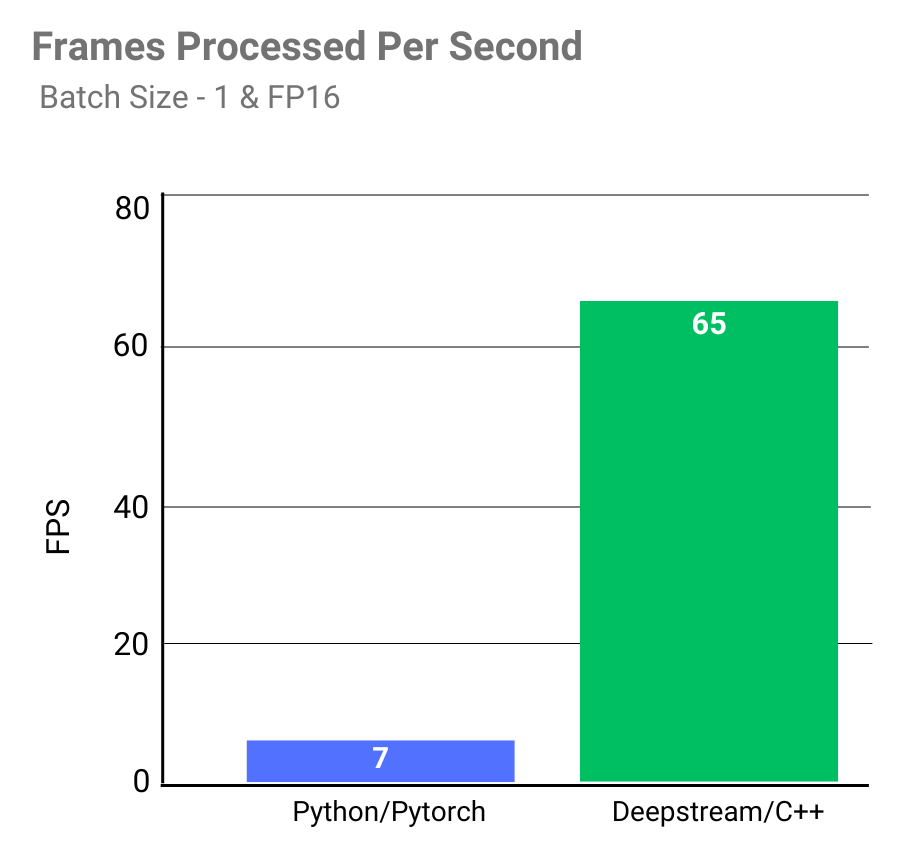
Deepstream pipeline is 9x faster in processing frames, it is able to process 65 frames/sec and far exceeds realtime Fps requirement. This speedup is due to parallel execution of multiple frames in the pipeline and optimized model inference runtime.
A python/pytorch pipeline will not be efficient for video frame processing in realtime, it will require more memory and faster expensive Gpus to increase frame processing speed.
(Deepstream and Nvinfer are Nvidia’s trademark)

