

Background
This blog outlines the advantages of compute attached to storage and reference architecture to implement it in the cloud with FPGAs.
Almost all the deep learning algorithms are very memory intensive and it takes more energy (power) to get data into and out of the CPU/GPU than the compute itself. Optimal scheduling of DMA is challenging owing to the several threads running to compute different parts of the network with dependencies rendering a lot of dead cycles. Moreover, 90% of the fully connected layer in ‘0’s weights, hence transferring these ‘0’s consume more energy. FPGA’s offer a healthy compromise between CPU/GPU and ASIC’s to implement fixed functions close to the memory. Storage can be attached near the cloud is the ideal choice for computing.
FPGA Advantages
There are several advantages to FPGA technology.
- The reconfigurability makes them more flexible than a custom-built ASIC
- The performance of the FPGA is higher than the CPU’s and GPU’s owing to the hardened pipeline
- Can perform Inline processing with low latency enabling real-time response
- GPU’s depend on batch processing for performance increasing the latency
- FPGA can be close to the data source/sink avoiding DMA overheads

Case for FPGA acceleration near Storage
The graph below shows the roofline for CPU (as reported by Google in its TPU-1 paper-2017). Utilization of CPU compute is maximum for the cases above 20 operations per byte. For cases where they are fully connected networks, it requires 1 Operation per 2 weight bytes (16-bit weights), thereby making the CPU wait for loading most of the time. whereas the database processing tasks is in IO-bound with the Operation per word can be accessed for non-in memory database. In many cases, the database sizes are large and preclude fully fitting into memory when there is less number of nodes.
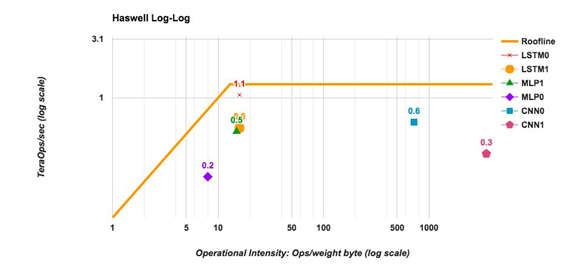
In doing, FPGA processing near the storage, the host processor receives only the results whereas the data can stay near the drives. Attachment of Caching in the memory to FPGAs helps to reuse the recently accessed data. This enables the implementation of very large databases/datasets with very less number of nodes and with very high performance reducing the overheads implementing clusters of processors.
Also, learn more about the data layer, check out Data Quality Improvement page
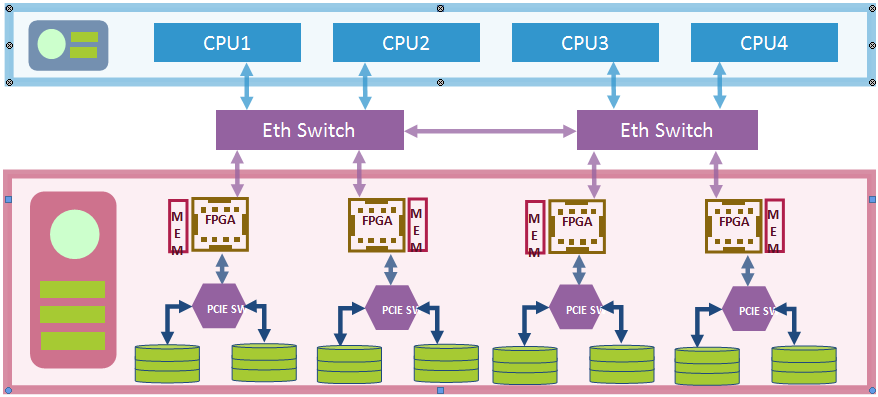
Moreover, the data can be back and forth with the SSD store to/from the FPGA without having to go to the network, alleviating IOPS at the processor, Network bandwidth at the Spine Switches.
Some of the operations on the data can be offloaded to the Accelerator as data is written into and read from Storage. Low latency and in-line processing have an advantage for such functionality. In order to reduce the footprint of the database, the functions like compression will be implemented in the accelerator.
Database Acceleration
Similar to the Deep-learning algorithms, Compute attached storage can be used to accelerate a lot of Database and Visualization functions. In order to process data in the FPGA, data fetched directly from the storage and only result in the CPU. This alleviates the IOPS requirement for the CPU and CPU just needs to issue a command to the FPGA.
FPGA processing latency is very low and without having to do any DMA transfers or pass through Network traffic, the latency is even lower enabling highly responsive response times. Moreover, FPGA can implement multiple threads with micro-engines enabling very high levels of parallelism for database tasks. FPGA can accelerate the search, another common database functions such as filtering, Arithmetic operations, etc.
Cloud Support for FPGA Acceleration
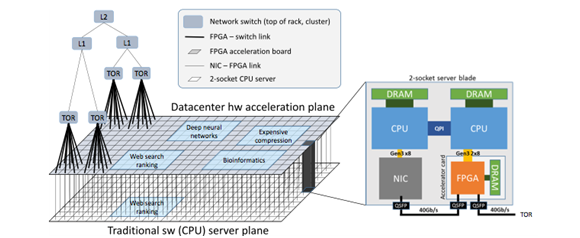
As per compute requirements in Cloud, FPGAs in cloud reprogrammed for different applications. For instance, the bing search is familiar with its use and efficiency.
Microsoft Azure has FPGA’s that connect to the TOR directly to fetch data without having to interrupt the Host processor enabling acceleration in line.
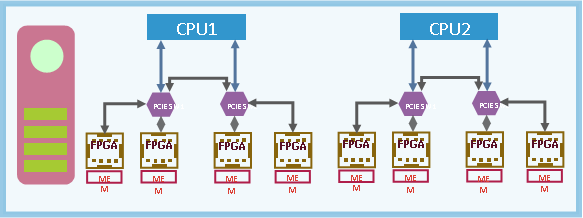
Amazon AWS provides F-1 instances and the instances can be built with SSD storage for fast access. However, AWS instances require that the Host processor schedule the DMA transfers. Here a Processor + FPGA + SSD Storage can form a Storage Node. It will perform with very high performance, low latency, and less network traffic.
Something got to give
Above all, One of the main disadvantages with the compute near Storage in Cloud storage acceleration with FPGA is that there could be new APIs for using the FPGA functions. For Deep-learning, it is relatively straightforward and functions can be offloaded at the layer-by-layer level or the complete network can be offloaded.
However for database acceleration either special offloading functions need to be called in-lieu of standard SQL commands. while a complete interpreter can be built similar to the memSQL and the backend can be implemented with FPGA functions.
Results
Storage acceleration for deep learning gave about 5x improvement in performance compared to running the model in GPU.
About 25x improvement in performance compared to running the model in CPU. Storage acceleration for SQL/ETL applications gave an improvement of over 25x compared to CPU.
Conclusion
Firstly, Moving to compute closer to the storage reduces the overall power consumption and efficiency. Certainly, it provides a very scalable architecture obviating the need for high-performance GPU’s and Switches for performing simple tasks. Secondly, Moving to compute closer to the storage is not confined to private clouds, but is also feasible in the current cloud architectures at Amazon AWS and Microsoft Azure. Furthermore, Gyrus has implemented several such FPGA offloading projects successfully.
バックグラウンド
このブログでは、FPGAを使用してクラウドに実装するためのストレージおよびリファレンスアーキテクチャに接続されたコンピューティングの利点について概説します。
ほとんどすべての深層学習アルゴリズムは非常に多くのメモリを消費し、コンピューティング自体よりもCPU/GPUにデータを出し入れするのにより多くのエネルギー(電力)を必要とします。 DMAの最適なスケジューリングは、ネットワークのさまざまな部分を計算するために実行されている複数のスレッドのために困難であり、依存関係によって多くのデッドサイクルが発生します。 さらに、完全に接続されたレイヤーの90%が「0」の重みであるため、これらの「0」を転送すると、より多くのエネルギーが消費されます。 FPGAは、CPU/GPUとASICの間の健全な妥協点を提供し、メモリの近くに固定機能を実装します。 ストレージはクラウドの近くに接続できるため、コンピューティングに最適です。
FPGAの利点
FPGA技術には、複数の利点があります。
- 再構成可能により、カスタムビルドのASICよりも柔軟性があります
- パイプラインが強化されているため、FPGAのパフォーマンスはCPUやGPUよりも高くなっています。
- 低レイテンシでインライン処理を実行でき、リアルタイム応答が可能
- GPUは、性能をバッチ処理に依存してレイテンシを増加させます
- FPGAは、DMAオーバーヘッドを回避してデータソース/シンクに近づけることができます
ストレージ付近のFPGAアクセラレーションのケース
その際、ストレージの近くでFPGA処理を行うと、ホストプロセッサは結果のみを受け取りますが、データはドライブの近くにとどまることができます。 メモリ内のキャッシングをFPGAにアタッチすると、最近アクセスしたデータを再利用できます。 これにより、ノード数が非常に少なく、性能が非常に高い非常に大規模なデータベース/データセットの実装が可能になり、プロセッサのクラスターを実装するオーバーヘッドが削減されます。
また、データレイヤーの詳細については、データ品質の改善ページをご覧ください。
その際、ストレージの近くでFPGA処理を行うと、ホストプロセッサは結果のみを受け取りますが、データはドライブの近くにとどまることができます。 メモリ内のキャッシングをFPGAにアタッチすると、最近アクセスしたデータを再利用できます。 これにより、ノード数が非常に少なく、性能が非常に高い非常に大規模なデータベース/データセットの実装が可能になり、プロセッサのクラスターを実装するオーバーヘッドが削減されます。
また、データレイヤーの詳細については、データ品質の改善ページをご覧ください。
データがストレージに書き込まれ、ストレージから読み取られるときに、データに対する操作の一部をアクセラレータにオフロードできます。 低レイテンシとインライン処理には、このような機能の利点があります。 データベースのフットプリントを削減するために、圧縮などの機能がアクセラレータに実装されます。
データベースアクセラレーション
深層学習アルゴリズムと同様に、コンピューティング接続ストレージを使用して、多くのデータベースおよび視覚化機能を高速化できます。 FPGAでデータを処理するために、データはストレージから直接フェッチされ、CPUのみになります。 これにより、CPUのIOPS要件が緩和され、CPUはFPGAにコマンドを発行するだけで済みます。
FPGAの処理レイテンシーは非常に小さく、DMA転送やネットワークトラフィックのパススルーを行う必要がないため、レイテンシーはさらに低くなり、応答性の高い応答時間が可能になります。 さらに、FPGAはマイクロエンジンを使用して複数のスレッドを実装できるため、データベースタスクの非常に高いレベルの並列処理が可能になります。 FPGAは、検索、フィルタリング、算術演算などの別の一般的なデータベース機能を高速化できます。
FPGAアクセラレーションのクラウドサポート
クラウドのコンピューティング要件に従って、クラウドのFPGAはさまざまなアプリケーション用に再プログラムされました。 たとえば、Bing検索はその使用法と効率に精通しています。
Microsoft Azureには、TORに直接接続してデータをフェッチするFPGAがあり、ホストプロセッサを中断することなく、インラインでアクセラレーションを実行できます。
Amazon AWSはF-1インスタンスを提供し、インスタンスは高速アクセスのためにSSDストレージで構築できます。 ただし、AWSインスタンスでは、ホストプロセッサがDMA転送をスケジュールする必要があります。 ここで、プロセッサ+ FPGA + SSDストレージはストレージノードを形成できます。 非常に高性能、低遅延、少ないネットワークトラフィックで動作します。
何かを与える必要があります
とりわけ、FPGAを使用したクラウドストレージアクセラレーションのストレージに近いコンピューティングの主な欠点の1つは、FPGA関数を使用するための新しいAPIが存在する可能性があることです。 深層学習の場合、これは比較的簡単で、関数をレイヤーごとのレベルでオフロードすることも、ネットワーク全体をオフロードすることもできます。
ただし、データベースアクセラレーションでは、標準のSQLコマンドの代わりに、特別なオフロード関数を呼び出す必要があります。 一方、完全なインタープリターはmemSQLと同様に構築でき、バックエンドはFPGA関数を使用して実装できます。
結果
深層学習のストレージアクセラレーションにより、GPUでモデルを実行する場合と比較して性能が約5倍向上しました。
CPUでモデルを実行する場合と比較して、パフォーマンスが約25倍向上します。 SQL / ETLアプリケーションのストレージアクセラレーションにより、CPUと比較して25倍以上の改善が見られました。
結論
まず、コンピューティングをストレージに近づけるように移動すると、全体的な電力消費と効率が低下します。 確かに、それは非常にスケーラブルなアーキテクチャを提供し、単純なタスクを実行するための高性能GPUとスイッチの必要性を排除します。 第二に、ストレージに近いコンピューティングへの移行はプライベートクラウドに限定されませんが、Amazon AWSとMicrosoft Azureの現在のクラウドアーキテクチャでも実行可能です。 さらに、GyrusはそのようなFPGAオフロードプロジェクトをいくつか成功裏に実装しました。

