

Background
This blog outlines the steps involved and things to care about for transfer learning a propensity to buy model.
Sales team members could inundate with several prospects. The best use of their time is by lead scoring and focus on the prospects that have the best chance to close. hence, A Propensity To Buy model helps the sales team members to identify and focus on the deals that have a high probability to close.
However every business has its own process, dependencies, nuances etc.and a generic model cannot suit everyone. Certainly, this blog tries to outline the steps and the data to showcase the system for a custom Propensity To Buy model.
Typical steps in a sale are a gradual progression from Leads to Accounts to Opportunities to Sale Closure. Propensity models work best for the leads in the opportunity class as they have data from the interactions and also from the external factors.
Feature List
The relevant data to be pulled into the model as part of the customization are
- Product Categories
- $ Value of the product
- Dates, duration, the purpose of Sales Meetings
- Contacts, their titles/designations
- Technical and Business decision-makers
- Interaction with Contacts
- Time Progression from lead, to contact to an opportunity
- Current Probability to Close % as presented by the salesperson
- Past purchase history per customer
- Database Access with a snapshot of the sales data
- Social Media and Web Analytics from a campaign
There are additional features that can be accessed from the public domain
- Seasonality
- Customers Business (Earnings reports)
- Customer Business Activity (Press Releases)
- Customer Public Sentiment
- Social Media Activity
- Contact Specific Activity
- Competition Activity
These two feature-lists are not an exhaustive list, but however is a guideline to the type of parameters to use. The actual feature list could be smaller in cases where we do not have quality, snapshot data.
Data Cleanup and Normalization
As a first step, the input data is scrubbed for anomalies and data that is either not complete or visibly wrong (data entry related) is removed. There are tools for viewing and analyzing the datasets that can be used for this process. There are simple models that indicate the cases where the data is an anomaly and they can be included or discarded depending on the scenario.
All the features need to populate based on an instance of time. It is quite possible that some of the equivalent features are not available and a nominal value is in place. Some of the new models have the ability to take blank input value for some features, indicating that, that particular feature information is not available.
Usually, Data normalize, at two levels. Firstly, At a high level, you can check the data for mean, median and variance to be at the expected level. If it is not, the data normalize with a curve or an equation. Secondly, at the next level, the data is made to be within a range of [0-1] for all features. The third-party data as mention above are also subjects to clean up and normalization as well.
The data for each feature can be discrete values like a rating/ranking 1-5, or a number indicating price/cost or independent union.
The details of such data layer processing are here
Model Development
In general, the first batch of propensity models had a very small number of features implementing logistic regression, giving decent results. With the vast amount of information available, there is potential for much more learned decisions with more complex models.
Furthermore, there are two ways to re-train the model with custom dataset. The first method is to transfer learning. In this process, all the hyperparameters of the models retain and the learning process relearns the weights occur. Here then the weights can initialize to new values or can start from the previous weights. The decision depends on the convergence speed and accuracy.
If the first method does not converge to an acceptable accuracy level, the hyperparameters themselves will be changed. Here the intention is not to transfer from the previous learning experiment. Also, If the new dataset size is large enough to converge, all new data will be used for learning. However, if the dataset is not large enough, some of the generic previous dataset entries can be used.
Moreover, the models can be fine-tuned as new data is collected as well. Snapshots of the dataset can be made from the live data and processed as noted above. Also, one of the important factors in model revision control is to have the ability to go back to recreate the models, as data sets are changing. Using a data framework such as the one at Gyrus would help.
Above all, the usability of the explainability model and the bias check models in order to cross-check the results do not need to change much. However, the explainability model might need re-training with new data.
Results
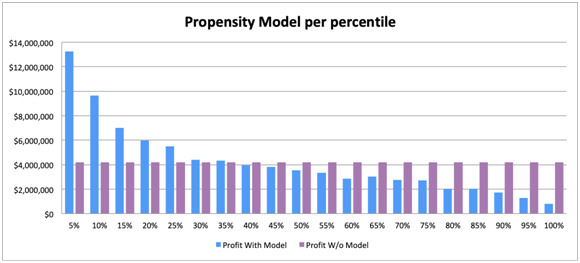
As a result, the below figure shows such exercise where the model saw a large upside in the net profit by focusing on the important accounts (up to 25 percentile). As can be seen from the chart, if there is an opportunity to approach, the result is similar to and without a model.
Conclusion
Gyrus has several similar models that can be referenced here.
Therefore, the propensity to buy is a very useful and productive model for real-life use-cases. also, it needs to tune/setup for the specific customer data to yield good results. Even more, in most cases of the box-model may not suit very well. Every model needs tools to efficiently do life cycle management and the corresponding explainability and bais check models.
バックグラウンド
このブログでは、モデルを購入する傾向を学習するために必要な手順と注意事項について概説します。
営業チームのメンバーは、多くの見込み客で溢れかえっています。 彼らの時間を最大限効率よく活用するのは、リードスコアリングを行い、成約する可能性が最も高い見込み客に焦点を当てることです。 したがって、購入傾向モデルは、営業チームのメンバーが成約する可能性が高い取引を特定して、集中するのに役立ちます。
ただし、すべてのビジネスには独自のプロセス、依存関係、ニュアンスなどがあり、一般的なモデルがすべての人に適しているわけではありません。 確かに、このブログでは、カスタムのPropensity ToBuyモデルのシステムを紹介するための手順とデータの概要を説明しようとしています。
販売の典型的なステップは、リードからアカウント、オポチュニティ、販売終了へと徐々に進行することです。 傾向モデルは、相互作用および外部要因からのデータを持っているため、商談クラスのリードに最適です。
機能リスト
カスタマイズの一部としてモデルに取り込まれる関連データは次のとおりです。
- 製品カテゴリ
- 製品価値
- 営業会議の目的、日付、期間、
- 連絡先、職責/名称
- 技術およびビジネスの意思決定者
- 連絡先との相互連絡
- リードに対する連絡開始から商談までの時間経過
- 営業担当者による現在の成約確率%
- 顧客毎の過去の購入履歴
- 販売データのスナップショットを使用したデータベースアクセス
- キャンペーンからのソーシャルメディアとウェブ分析
パブリックドメインからアクセスできる以下の追加機能があります。
- 季節性
- 顧客ビジネス(収益レポート)
- 顧客の事業活動(プレスリリース)
- 顧客の世論
- ソーシャルメディア活動
- 顧客の特定活動
- 競合他社の活動
これらの2つの機能リストは完全ではありませんが、使用するパラメーターのタイプのガイドラインです。 品質のスナップショットデータがない場合、実際の機能リストは小さくなる可能性があります。
データのクリーンアップと正規化
最初のステップとして、入力データの異常をスクラブし、完全ではないか、目に見えて間違っている(データ入力に関連する)データを削除します。 このプロセスに使用できるデータセットを表示および分析するためのツールがあります。 データが異常である場合を示す単純なモデルがあり、シナリオに応じて、それらを含めたり破棄したりできます。
すべての機能は、時間のインスタンスに基づいて設定する必要があります。 同等機能の一部が利用できず、公称値が設定されている可能性があります。 一部の新しいモデルには、一部の機能に対して空白の入力値を取得する機能があり、特定の機能情報が利用できないことを示しています。
通常、データは2つのレベルで正規化されます。 まず、高レベルでは、平均、中央値、分散のデータをチェックして、期待されるレベルにすることができます。 そうでない場合、データは、曲線または方程式で正規化されます。 次に、次のレベルでは、すべての機能についてデータが[0-1]の範囲内に収まるように作成されます。 上記のサードパーティのデータも、クリーンアップと正規化の対象になります。
各機能のデータは、評価/ランキング1〜5のような離散値、または価格/コストまたは独立した結合を示す数値にすることができます。
このようなデータレイヤー処理の詳細はこちら。
モデル開発
一般に、傾向モデルの最初のバッチには、ロジスティック回帰を実装する非常に少数の機能があり、適切な結果が得られました。 膨大な量の情報が利用可能であるため、より複雑なモデルを使用して、より多くの意思決定を学ぶ可能性があります。
さらに、カスタムデータセットを用いて、モデルを再トレーニングする方法は2つあります。 最初の方法は、学習を転送することです。 このプロセスでは、モデルのすべてのハイパーパラメータが保持され、学習プロセスは重みが発生することを再学習します。 ここで、重みは新しい値に初期化することも、以前の重みから開始することもできます。 決定は、収束速度と精度に依存します。
最初の方法が許容可能な精度レベルに収束しない場合、ハイパーパラメータ自体が変更されます。 ここでの意図は、前の学習実験から移行することではありません。 また、新しいデータセットサイズが収束するのに十分な大きさである場合、すべての新しいデータが学習に使用されます。 ただし、データセットが十分に大きくない場合は、以前の一般的なデータセットエントリの一部を使用できます。
さらに、新しいデータも収集されるため、モデルを微調整できます。 データセットのスナップショットは、ライブデータから作成し、上記のように処理できます。 また、モデルリビジョン管理の重要な要素の1つは、データセットが変化しているときに、モデルを再作成するために戻ることができることです。 Gyrusのようなデータフレームワークを使用すると役立ちます。
とりわけ、結果をクロスチェックするための説明可能性モデルとバイアスチェックモデルの使いやすさは、それほど変更する必要はありません。 ただし、説明可能性モデルでは、新しいデータを使用して再トレーニングする必要がある場合があります。
結果
その結果、下図は、モデルが重要なアカウント(最大25%)に焦点を当てることにより、純利益に大きな上昇が見られたような演習を示しています。 グラフからわかるように、アプローチする機会があれば、結果はモデルと同様であり、モデルがない場合です。
結論
Gyrusは、参照できる同様のモデルを複数保有しています。
したがって、購入傾向は、実際のユースケースにとって非常に有用で生産的なモデルです。 また、良好な結果を得るには、特定顧客データに合わせて調整/設定する必要があります。 さらに、ほとんどの場合、ボックスモデルはあまり適していません。 すべてのモデルには、ライフサイクル管理とそれに対応する説明可能性および基礎チェックモデルを効率的に実行するためのツールが必要です。

