

Background
This blog briefs the Importance of Data Discipline and Governance for an organization where a large amount of data processed daily.
Data is the new Oil. Companies should treasure data. The new class of powerful Machine Learning (ML) and Artificial Intelligence (AI) algorithms are data-hungry and are as good as the data provided to them. Several useful (profitable) insights can be derived from data across the organization benefiting different departments and initiatives.
However, there are several challenges in trying to have a discipline about capture, storage, access and usage of data. Even more, this blog tries to cover some principles and advantages in data governance of a large organization.
Data and ML/AI algorithms in Data discipline Implementation
Most of the models we deal with today are statistical and are predicated on the data.
ML/AI algorithms are good at exploring and exploiting relationships when there are a large number of touchpoints/features. For example, an external customer for one department could be a vendor for another department and by looking at the information together; ML models can make use of this relationship to the advantage of the company. Similar to a vendor can be supplying two different departments.
To learn more about our AI framework models, check out Gyrus AI Framework Modules
Team Organization
It is paramount to have high-quality data instead of large datasets. Open-source datasets or datasets loosely connected are mostly in use for developing an openly available model. Usual open-source datasets do not have the quality from real-life use cases. Either they are not complete or they are not accurate on all counts.
In order to set up the data guideline for the company of a large organization. a chief data officer CDO or equivalent at the company level to maintain is desirable. CDO and his team can formulate the best practices, basic set of rules about the collection, storage, security, usage, and distribution. They can also have tools/software for implementing these prescribed practices.
In practice, each of the divisions could have their own data requirements, which could be different from the CDO’s generic goal. Therefore, it is highly desirable to have data engineers at the division level to address the specific needs of the division, still complying with the broader vision set by the CDO.
On the contrary, moving all the Data engineers into one group under CDO could be counter the productive in serving the needs of the divisions (though that scheme has potential to have higher efficiency (reuse), in the long run, the division needs tend to be ignored in-lieu of too broad goals)
To learn more about data governance, Check out our data discipline in large organization blog
Data Organization
One of the biggest challenges is that we are not able to predict the future uses of data. New models can use data in a completely different way. So there are two ways of collecting data with some trade-offs.
a) Collect all events with time stamps
1. This is storage intensive as we collect all the events coming in.
2. However, provides flexibility to have any algorithms developed in the future with this data
b) Collect processed events
a. With the intuition/prior history of what sort of signals is important, the signals are derived and stored.
b. Naturally, this takes lesser disk space.
An example of a model is whether to store the complete video in a surveillance case or collect important signals to when there is an action takes place in a video or to store and record only the actions in textual form.
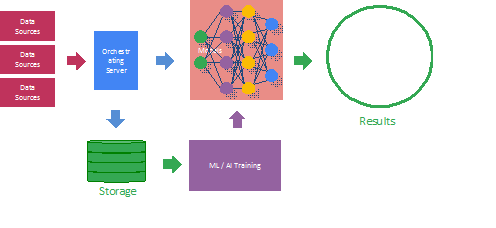
Model Security
Seeing the value of data, several services, and ML/AI model development organizations are willing to work with companies, which have data/datasets with the idea to take back the learned model. The learned model is in a way a representation of the data used to learn it and it can be licensed to other companies in a similar field. This is a huge disadvantage to the Organization giving data as they will be empowering their competitor with their data. It is the responsibility of every organization to protect its data and derived models.
Vendor-specific data is proprietary and is governed by Non-Disclosure agreements with huge ramifications. The models derived from this data can inadvertently leak the base information. So transferring models to external parties can be a violation of confidentiality of the vendor data. Differential privacy is a technique in ML/AI that tests and prevents leaking individual information through models. Moreover, the administration of models is essential to avoid leakage of information, whereas models given out for external usage. In general quality, datasets have become so much value that there are companies willing to pay for datasets either with direct $$ or using Crypto-Currency.
Conclusion
As a result of Data discipline, Quality data powers ML/AI algorithms. Companies should have a data policy across the company and at each department level to capture, store, protect, and use data. Models derived out of this data has the potential to contain the vendor/partner data and proprietary information. Therefore, the protection of models is important, for the reason that not to lose powerful information to competitors.
バックグラウンド
このブログでは、大量のデータが毎日処理される組織にとってのデータの規律とガバナンスの重要性について簡単に説明しています。
データは新しいオイルです。 企業はデータを大切にする必要があります。 新しいクラスの強力な機械学習(ML)および人工知能(AI)アルゴリズムはデータを大量に消費し、提供されたデータと同じくらい優れています。 さまざまな部門やイニシアチブに利益をもたらす組織全体のデータから、いくつかの有用な(有益な)洞察を引き出すことができます。
ただし、データのキャプチャ、保存、アクセス、および使用について規律を持たせるには、いくつかの課題があります。 さらに、このブログでは、大規模な組織のデータガバナンスにおけるいくつかの原則と利点について説明しています。
データ分野の実装におけるデータとML/AIアルゴリズム
今日扱っているモデルのほとんどは統計的であり、データに基づいています。
ML/AIアルゴリズムは、タッチポイント/機能が多数ある場合に、関係を調査して活用するのに適しています。 たとえば、ある部門の外部顧客が別の部門のベンダーであり、情報を一緒に見ることができます。 MLモデルは、この関係を利用して会社の利益を得ることができます。 ベンダーと同様に、2つの異なる部門に供給できます。
AIフレームワークモデルの詳細については、Gyrus AIフレームワークモジュールをご覧ください。
チーム組織
大規模なデータセットではなく、高品質のデータを用意することが最も重要です。 オープンソースのデータセットまたは疎結合のデータセットは、主にオープンに利用可能なモデルの開発に使用されています。 通常のオープンソースデータセットは、実際のユースケースからの品質を備えていません。 それらは完全ではないか、すべての点で正確ではありません。
大規模な組織の会社のデータガイドラインを設定するため。 維持するために、企業レベルの最高データ責任者CDOまたは同等のものが望ましい。 CDOと彼のチームは、収集、保存、セキュリティ、使用法、および配布に関するベストプラクティス、基本的なルールセットを策定できます。 彼らはまた、これらの規定された慣行を実施するためのツール/ソフトウェアを持つことができます。
I実際には、各部門には独自のデータ要件があり、CDOの一般的な目標とは異なる可能性があります。 したがって、CDOによって設定されたより広いビジョンに準拠しながら、部門の特定のニーズに対応する部門レベルのデータエンジニアがいることが非常に望ましいです。
それどころか、CDOの下ですべてのデータエンジニアを1つのグループに移動することは、部門のニーズに対応する上で生産性に反する可能性があります(ただし、そのスキームはより高い効率(再利用)を持つ可能性がありますが、長期的には、部門のニーズは 広すぎる目標の代わりに無視されます)
Tデータガバナンスの詳細については、大規模な組織のブログでデータ規律を確認してください。
データ編成
大きな課題の1つは、データの将来の使用を予測できないことです。 新しいモデルでは、まったく異なる方法でデータを使用できます。 したがって、いくつかのトレードオフを伴うデータ収集には2つの方法があります。
a)タイムスタンプ付きのすべてのイベントを収集する
1.入ってくるすべてのイベントを収集するため、これはストレージを大量に消費します。
2.ただし、このデータを使用して将来的に任意のアルゴリズムを開発できる柔軟性を提供します
b)処理されたイベントを収集する
a. どのような種類の信号が重要であるかという直感/以前の履歴を使用して、信号が導出され、保存されます。
b. 当然、これにより必要なディスク容量は少なくなります。
モデルの例としては、ビデオ全体を監視ケースに保存するか、ビデオでアクションが発生したときに重要な信号を収集するか、アクションのみをテキスト形式で保存して記録するかがあります。
モデルのセキュリティ
データの価値を見て、いくつかのサービス、およびML / AIモデル開発組織は、学習したモデルを取り戻すというアイデアを持ったデータ/データセットを持っている企業と協力する用意があります。 学習されたモデルは、ある意味でそれを学習するために使用されたデータの表現であり、同様の分野の他の企業にライセンス供与することができます。 これは、データを提供する組織にとって大きな不利益です。競合他社にデータを提供することになるからです。 データと派生モデルを保護することは、すべての組織の責任です。
ベンダー固有のデータは独自のものであり、重大な影響を伴う機密保持契約に準拠しています。 このデータから派生したモデルは、誤って基本情報を漏らす可能性があります。 したがって、モデルを外部の関係者に転送すると、ベンダーデータの機密性が侵害される可能性があります。 差分プライバシーは、モデルを介した個人情報の漏洩をテストおよび防止するML/AIの手法です。 さらに、モデルの管理は情報の漏洩を防ぐために不可欠ですが、モデルは外部で使用するために配布されます。 一般的な品質では、データセットは非常に価値が高くなっているため、直接$$または暗号通貨を使用してデータセットに支払うことをいとわない企業があります。
結論
データ規律の結果として、品質データはML / AIアルゴリズムを強化します。 企業は、データをキャプチャ、保存、保護、および使用するために、企業全体および各部門レベルでデータポリシーを設定する必要があります。 このデータから派生したモデルには、ベンダー/パートナーのデータと専有情報が含まれる可能性があります。 したがって、競合他社に強力な情報を失わないために、モデルの保護は重要です。

